重点#
- 知道四种替换算法
- LRU 算法的原理、计算
1. 先进先出(FIFO)#
cache 数比主存块数少得多,因此,往往多个主存块会映射到同一个 cache 中。当新的一个主存块复制到 cache 时,cache 中的对应可能已经全部被占满,此时,必须选择淘汰掉一个 cache 行中的主存块。
FIFO 算法的基本思想是:总是选择淘汰最早装 cache 的主存块。即先装入 cache 的主存块优先被替换。
这种算法实现起来较方便,但不能正确反映程序的访问局部性,因为最先进入 cache 的主存块也可能是目前经常要用的,因此,这种算法有可能产生较大的缺失率,命中率不高。
2. 随机替换算法#
随机(RAND)算法:随机选择一个 cache 行进行替换。实现简单,但未利用程序访问的局部性原理,命中率通常较低。
3. 最不经常使用算法#
最不经常使用算法,LFU 算法的基本思想是:优先替换缓存中最近一段时间内访问次数最少的 cache 行。
即每行设立一个计数器,当 cache 行存入主存块时,计数器初始化为 0,每次访问该 cache 行时计数器加 1;替换时选择计数器值最小的 cache 行进行替换。
他关注的是总共用了多少次,而接下来的重点 LRU 关注的是 cache 行最近是否使用过。
4. LRU 算法#
LRU 算法为最近最少使用算法,它的思想是:淘汰最近最久没被访问的 cache 行,看访问间隔,而不是访问次数。
例如有四个缓存行,但 CPU 要顺序访问 个主存块,设为主存块 。顺序访问下,主存块 被顺序存入 cache 并送入 CPU;接下来访问主存 ,显然第五个主存块不在 cache 里,此时要把主存块 存入 cache ,由于是顺序读取,因此这段时间内最久没被访问到的主存块是主存块 (存储在 cache 行 1),因此主存块 会存入 cache 行 1,替换掉主存块 。
4.1. 具体实现#
查看这个例子:设主存中的五块主存: 要存入缓存,而缓存行只有 行。设访问序列为:。
机器实现 LRU 算法时,需要维护一组计数器,每个缓存行有一个计数器,也称为 LRU 位,其大小和 cache 组大小(组内 cache 行数)有关,一般 路相联映射的 LRU 位为 ,例如 路相联映射的 LRU 位就有 。
下图位依次访问题设序列时,四个 cache 行的存储块序号的变化。虚线右侧是每一个缓存行的 LRU 位,它的更新规则有以下三条,也是重点:
- 缓存命中时,命中的缓存行的计数器(即 LRU 位)清理,其他缓存行的计数器值如果比它低的,则加 ;比它高(或相同)的值不变。
- 未命中但有空闲缓存行时,则新装入的缓存行的计数器置为 ,其他非空闲行的计数器加
- 未命中且无空闲行时,选中计数值最大的 cache 行进行替换,新装入的行的计数器置为 ,其余加
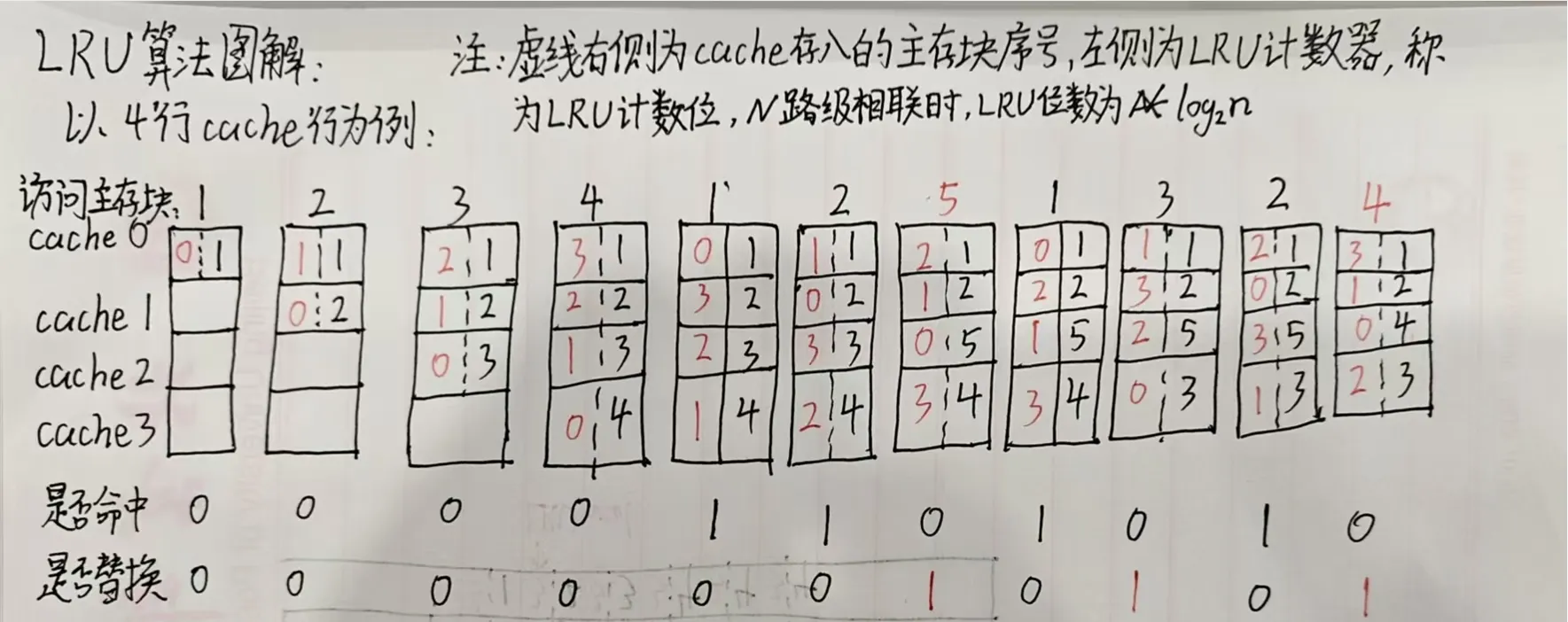
观察图中顺序访问 时,根据 LRU 更新规则,可以看到缓存未命中且有空闲行时,每装入新的主存块, 其余行的 LRU 位的值加 。以 cache 0 为说明,当主存块 存入时,cache 0 的 LRU 位(记为 )从 ;主存块 存入, 变为 。
观察后续再次访问主存块 时,缓存命中,根据更新规则, 置为 ,同时由于 的值最大,因此其余三行的 LRU 位均加 。再次访问主存块 ,缓存命中,此时 置为 ,其余三行加 1。
出现替换:此时访问主存块 ,缓存缺失,查看每一个缓存行里的计数值,发现 值最大,因此主存块 替换 cache 3 里存储主存块 ,同时 置为 ,其余行加 (因为没 值最大)。
后续的替换和 LRU 位的更新,均和描述的原理一致,不再赘述。
现在回到更新规则:

关于第一条,可能有个疑问:为什么比其低的计数值不变?
每行都需要一个 LRU 位(计数器),因此硬件成本已经够高。如果命中时,除了命中行计数清零外,其余行均加 ,则会增加计算成本:其实比命中行计数值还高的缓存行的值可以不变,不影响更新逻辑。
以例子说明,请看第 次访问,如果此时访问的主存块不是 ,而是 ,此时如果不遵守 “其余不变” 的规则,那么 cache 2 的计数值置为 0,其余全部加 1,此时 cache 1 的计数值从 3 变为 4:但这是不必要的。根据 LRU 的替换原则:始终选择计数值最大的 cache 行进行替换。因此不论 cache 1 的计数值是 3 还是 3,它始终是最大的,如果下一次访问发生缓存缺失,必然是 cache 1 被替换。
这可得到一个结论:计数值的最大值等于缓存行的行数 - 1。图中缓存行有 4 行,因此计数值的最大值为 3。
这样设计的好处是:不需要浪费硬件资源去做冗余的加法计算,也就是:命中时,命中行的计数值清零,其余缓存行的计数值如果比它小,则加一;比它大,则不变。
4.2. 例题#

由题,主存块大小为 字,因此缓存划分为 ,主存空间划分为 ,由此可得
连续访问 4352 个主存单元,一个主存块 64 个字,因此一共连续访问 即 68 个主存块()。
每个缓存组有 4 行,一共 16 组,那么主存块 共享第 0 组缓存, 共享第 1 组缓存, 共享第 2 组缓存, 共享第 3 组缓存。这 4 组在每次重复读取时都会出现缓存替换,因为组内缓存行数只有 4 ,而有 5 个主存块映射到同一组里。
为方便称呼,设组 为 ,行 为 ,主存块 为 。第一次访问时,由于 cache 为空,因此 到 都可存入缓存:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 0 | 16 | 32 | 48 |
| 组 1 | 1 | 17 | 33 | 49 |
| 组 2 | 2 | 18 | 34 | 50 |
| 组 15 | 15 | 31 | 47 | 63 |
此时还有 没有访问。访问 时,出现 cache 缺失,且组 0 已满,需要执行 LRU 替换。考察组 0,存入 时, 的计数值应该是最大的,为 ,因此 存入 ,替换掉 。同理, 替换 , 替换 , 替换 ,第一次访问结束后缓存的存储内容为:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 064 | 16 | 32 | 48 |
| 组 1 | 165 | 17 | 33 | 49 |
| 组 2 | 266 | 18 | 34 | 50 |
| 组 3 | 367 | 19 | 35 | 51 |
| 组 4 | 4 | 20 | 36 | 52 |
| ····· | ··· | ··· | ··· | ··· |
| 组 15 | 15 | 31 | 47 | 63 |
第一次访问一共出现 68 次缓存缺失。
接下来进行第一次循环访问:
- 访问 ,出现缓存缺失:原来 cache 的组 0 行 0 存的是 ,但访问 时已被替换。此时需要将 存入 cache,由 LRU 算法,本次被替换的是 ,因为组 0 里,最久未被访问的是行 1,计数值为
- 访问 ,缓存缺失:情况和 相同, 替换
- 顺序访问 ,: 替换 , 替换 。
- 访问 ,缓存命中: 位于组 4 行 0
在访问到 前:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 64 | 160 | 32 | 48 |
| 组 1 | 65 | 171 | 33 | 49 |
| 组 2 | 66 | 182 | 34 | 50 |
| 组 3 | 67 | 193 | 35 | 51 |
| 组 4 | 4 | 20 | 36 | 52 |
| ····· | ··· | ··· | ··· | ··· |
| 组 15 | 15 | 31 | 47 | 63 |
当访问到 时,由于 已被 替换,因此出现缓存缺失:根据 LRU 算法,此时 会替换 存入组 0 行 2:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 64 | 160 | 3216 | 48 |
同理,,, 均出现缓存缺失,由于组内行满触发 LRU 替换算法,依次存储在组 1、组 2、组 3 的行 2,替换掉 ,,:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 64 | 0 | 3216 | 48 |
| 组 1 | 65 | 1 | 3317 | 49 |
| 组 2 | 66 | 2 | 3418 | 50 |
| 组 3 | 67 | 3 | 3519 | 51 |
| 组 4 | 4 | 20 | 36 | 52 |
| ····· | ··· | ··· | ··· | ··· |
| 组 15 | 15 | 31 | 47 | 63 |
访问 ,缓存命中; 一直到 ,又触发缓存缺失:因为前面访问 时 被替换。因此根据 LRU 算法,本次 存储的位置为组 0 行 3,替换掉 :
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 64 | 160 | 3216 | 4832 |
同理, ,, 均出现缓存缺失,由于组内行满触发 LRU 替换算法,依次存储在组 1、组 2、组 3 的行 2,替换掉 ,,。
而到了 ,缓存命中; 到了 ,触发缓存缺失,此时 替换 ,存储在组 0 行 0。对于组 1 到组 3,也是同样的情况: 替换存入组 1 行 0:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 6448 | 0 | 16 | 32 |
| 组 1 | 6549 | 1 | 17 | 33 |
| 组 2 | 6650 | 2 | 18 | 34 |
| 组 3 | 6751 | 3 | 19 | 35 |
| 组 4 | 4 | 20 | 36 | 52 |
| ····· | ··· | ··· | ··· | ··· |
| 组 15 | 15 | 31 | 47 | 63 |
而 到 均缓存命中;到了 ,发生缓存缺失,此时 替换 ,存入组 0 行 1。
最终,第一次重复访问的缓存结果为:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 48 | 064 | 16 | 32 |
| 组 1 | 49 | 165 | 17 | 33 |
| 组 2 | 50 | 266 | 18 | 34 |
| 组 3 | 51 | 367 | 19 | 35 |
| 组 4 | 4 | 20 | 36 | 52 |
| ····· | ··· | ··· | ··· | ··· |
| 组 15 | 15 | 31 | 47 | 63 |
对比刚开始的缓存内容:
| 组号/行号 | 第 0 行 | 第 1 行 | 第 2 行 | 第 3 行 |
|---|---|---|---|---|
| 组 0 | 064 | 16 | 32 | 48 |
| 组 1 | 165 | 17 | 33 | 49 |
| 组 2 | 266 | 18 | 34 | 50 |
| 组 3 | 367 | 19 | 35 | 51 |
| 组 4 | 4 | 20 | 36 | 52 |
| ····· | ··· | ··· | ··· | ··· |
| 组 15 | 15 | 31 | 47 | 63 |
因此可以统计出一个规律:
- 由于主存块 共享第 0 组缓存,而单次重复访问结束后,主存块 0 会被主存块 64 替换,而下一次重复访问开始时,从 开始,因此一定出现缓存缺失。
- 而访问到 时,一定又会发生缓存缺失( 刚替换掉 );同理,主存块 32、48、64 均会缺失
- 到最后, 会替换掉 ,导致下一次重复访问开始时, 又缓存缺失
因此,考察组 0,其每次重复访问时都会发生 5 次缓存缺失。而组 1、2、3 的情况和组 0 相同,**所以每次重复访问时总缺失次数为 次 **
查看题目,以字为访问单位(因为 CPU 最终读取的是某个特定的块内地址的数据单元,而不是整个主存块),注意:当发生缓存缺失时,会把整个主存块都存入缓存对应的行,每一个缺失的主存块只有第一个字缺失,因为 CPU 只会按字读取数据单元。以下的计算都是以字为单位,计算访问次数和缺失次数。
其要求重复访问 10 次,则总访问次数为 次。每次重复访问时,都是组 0、1、2、3 发生缓存缺失,缺失次数为 20 次,总的缓存缺失次数为 ,命中率
设主存访问时间和 cache 访问时间分别为 ,,则 。采用缓存—主存层后,平均存取时间 ,
速度提高了:
提高了 倍。