重点#
- 三种映射方法的原理
- 三种映射方法的 CPU 访存过程
- 三种映射方法的例题计算
- 级相联是重点,直接映射、全相联都是级相联的特殊形式
1. 简要#
前文提到,
有效位
在系统启动或复位时,每个 cache 行都为空,其中的信息无效,只有装入了主存块后信息才有效。为了说明 cache 行中的信息是否有效,每个 cache 行需要一个有效位(valid bit)。有了有效位,就可通过将有效位清零来淘汰某 cache 行中的主存块,称为冲刷(flush),装人一个新主存块时,再使有效位置 1。
标记位
由于 Cache 行数远少于主存块数,Cache 只能存放主存中部分块的副本。为识别每个 Cache 行对应哪个主存块,需要为每行设置一个标记位,记录该缓存行存储的主存储块的编号。
同时设置一位有效位,用于指示该行数据是否有效。系统启动或复位时,所有 Cache 行均无效;仅当主存块被装入某 Cache 行后,其有效位才置为 1。
在将主存块复制到 cache 时,主存块和 cache 之间必须遵循一定的映射规则。这样,CPU 要访问某个主存单元时,可依据映射规则到 cache 对应的行中查找信息,而不用在整个 cache 中查找。
根据不同的映射规则,主存块和 cache 行之间有以下 3 种映射方式。
- 直接(direct):每个主存块映射到 cache 的固定中。
- 全相联(full associate):每个主存块映射到 cache 的任意中。
- 组相联(set associate):每个主存块映射到 cache 固定组的任意行中。
2. 直接映射#
2.1. 原理#
直接映射的思想是:将多个主存块固定映射到同一个缓存行。因为缓存行的数量一般少于主存块的数量,所以只能多个主存块共享同一份缓存行。
更具体地说,将主存块划分为多个块群,每一个块群里,主存块的数量和缓存行的数量相同。这样每一个块群里的第一个主存块共享缓存里的第一个缓存行,每一个块群里的第二个主存块共享缓存里的第二个缓存行,以此类推。(从主存到缓存)
那么这会引出第二个问题:既然有多个主存块共用同一个缓存行,那么用什么标识区分缓存行里存储的是哪一个存储块?(从缓存行逆推主存块)
显然,当 CPU 访问缓存的特定数据时,需要三个参数:
- 缓存行标识(cache 行号):用于标识 CPU 要访问的是哪一个缓存行
- 主存块标识(标记,也称 tag):用于标识 CPU 访问的缓存行,实际存储的是哪一个主存块的数据。
- 块内地址:(假设前两个参数正确,已找到正确的主存块。)用于标识 CPU 访问的目标主存块里,具体的数据,即哪一个字节的数据。

2.2. 实现方法#
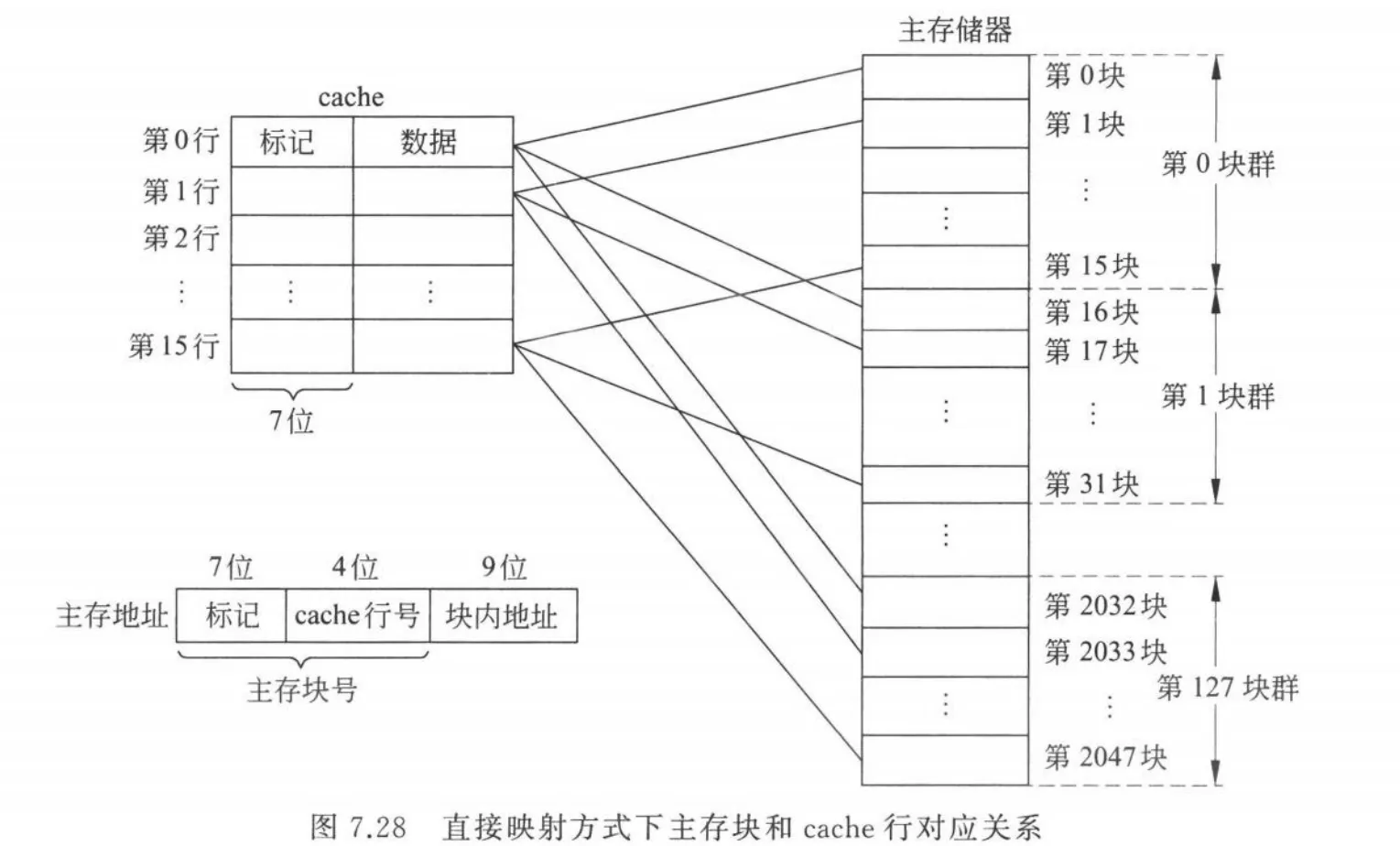
通常 cache 的行数是 的 次幂,假设 cache 有 行,主存有 行。则主存可以划分为 个块群,每一个块群的主存块数量为 个。那么第 块、第 块、第 块 都对应着 cache 的第 行。
则 cache 行号即主存块号 中的低 位。(从主存到 cache)
在 cache 里,可以给每一 cache 行设置一标记(tag),tag 长度为 位,则 ,像上文所述,用于标识当前 cache 行存储的是哪一个主存块的数据。(从 cache 到主存)
而块内地址为 位,它和主存块的行数(主存块地址)、cache 行数无关,是主存块里的某一个字节的地址。例如主存块大小为 ,则 。
显然,主存地址显然可被分为下图的三个字段:
以一个例子说明:假设主存有 行,cache 有 行,则 。
主存块大小为 ,则 。
那么主存可分为 个块群,即第 、、、、 行主存块共用第 行 cache 行。
| 主存块号 | 二进制 | tag | cache 行号 | 块内地址 |
|---|---|---|---|---|
| 第 0 块 | 00 0000 00 | 00 0000 | 00 | 0000~1111 |
| 第 4 块 | 00 0001 00 | 00 0001 | 00 | 0000~1111 |
| 第 8 块 | 00 0010 00 | 00 0010 | 00 | 0000~1111 |
| 第 252 块 | 11 1111 00 | 11 1111 | 00 | 0000~1111 |
观察 cache 行号,可以知道它们都使用的第 0 行 cache(行号为 00),而 tag 不同。因此可借助 tag 判断该 cache 行缓存的是哪一个主存块。
假设 CPU 要访问的完整地址是 ,二进制地址为 00 0010 00 0010,则访问的是主存块编号为 00 0010 00 里的第 个字节的内容。
2.3. CPU 访存过程#
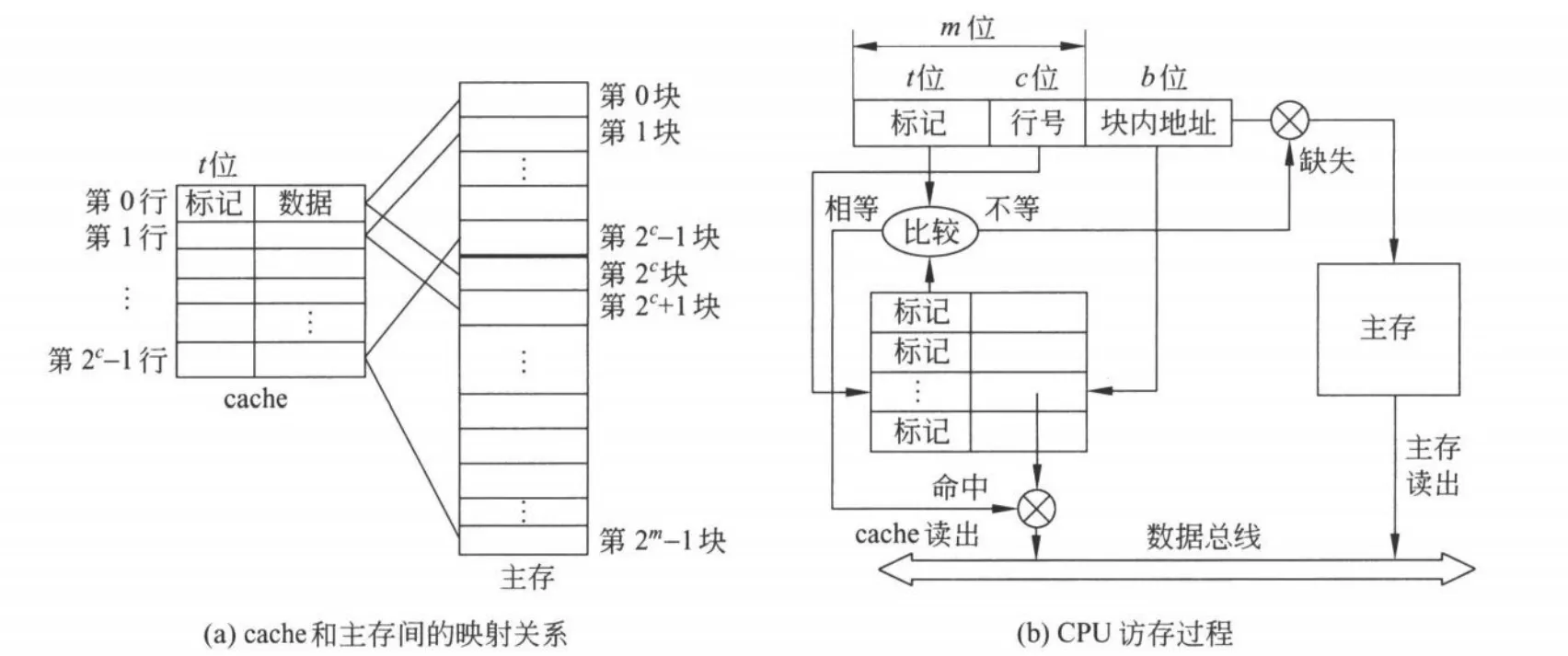
访存过程如下:
- 首先根据主存地址中间的 位,直接找到对应的 cache 行。
- CPU 将对应 cache 行中的标记和主存地址的高 位标记进行比较,若相等并有效位为 ,则称本次访问 cache 命中;此时,根据主存地址中低位的块内地址,在对应的 cache 行中存取信息。
- 若不相等或有效位为 ,则称为缓存缺失,此时,CPU 从主存中读出该地址所在的一块信息送到对应的 cache 中,将有效位置为 ,并将 tag 设置为地址中的高 位,同时将该地址中的内容送入 CPU。
2.4. 例题#




访问 单元的过程如下,首先根据地址中间 位 0010,找到 cache 第 2 行,因为 cache 为空,所以每个 cache 行的有效位都为 0,因此,不管第 2 行的标志是否等于 0000 001,都不命中。此时,将 0240CH 单元所在的第 18 块复制到 cache 第 2 行,并置有效位为 ,置标记为 0000 001(表示当前 cache 行存储的主存块取自主存第 块群中对应的主存块)。
2.5. 小结#
直接映射的优点:容易实现,命中时间短(只需根据 cache 行号就能直接找到对应的主存块)。
但也有缺点:因为是多对一的映射方式,因此会导致频繁的掉进调出。例如 “2.2. 实现方法” 中的例子,第 个主存块(设为 )和第 个主存块(设为 )都映射到第 cache 行(设为 ),即使其它 cache 行空闲,都无法使得这两个主存块同时存入 cache。
如果一个循环指令需要频繁调用这两个主存块的数据,那么 cache 命中率就会很低,因为访问 后, 存储的是 的数据;下一次要访问 ,则发生缓存缺失,需要从主存里复制 到 ;再下一次要访问 ,显然又发生缓存缺失。
3. 全相联#
3.1. 原理#
全相联映射删除了直接映射的 cache 行号字段,只保留 tag 字段和块内地址。
它的基本思想是:一个主存块可以存储在 cache 的任意一行,只根据 tag 字段查找目标主存块。
由于不存在 cache 行号字段,因此需要令 CPU 需要的目标地址的高 位(tag 字段)去和 cache 里的所有行的 tag 字段进行比对。
这种方式不存在多对一的约束,只要 cache 存在空闲(有效位为 ),就不会产生冲突,因此块冲突的概率最小,空间利用率最高,命中率也很高。
当 cache 行已满,无空闲时,需要使用替换算法进行缓存行替换,后续介绍替换算法。
3.2. 例题#
假定主存和 cache 之间采用全相联映射,块小为 ,按字节编址。cache 数据区容量为 ,主存地址空间为 。问:主存地址如何划分?要求用图表示主存块和 cache 行之间的映射关系,并说明 CPU 对主存单元 的访问过程。
解答:
cache 数据区容量为 ,主存地址空间为 。
因此 位的主存地址空间可划分为:位数是 的 tag 字段;位数 的块内地址字段。

主存地址划分以及主存块和 cache 行之间的对应关系如图所示。
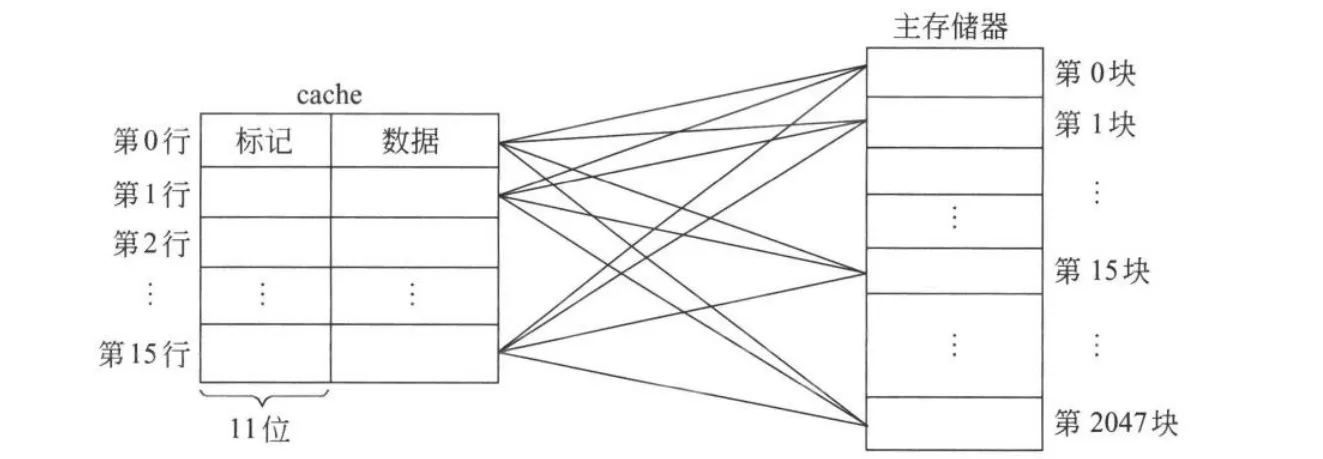
中间的连接线标识主存里的任一个主存块可存储在 cache 里的任一行

访问 0240CH 单元的过程如下:
首先将高 位标记 0000 0010 010 与 cache 中每个行的标记进行比较,若有一个相等并且对应有效位为 ,则缓存命中,此时,CPU 根据块内地址 0 0000 1100 从该行中取出信息。
若该 tag 和 cache 里的任一行 tag 不匹配或者有效位为 ,则缓存缺失,此时,需要将 0240CH 单元所在的主存的第 0000 0010 010 块(即第 18 块)复制到 cache 的任何一个空闲行中,并置有效位为 ,置 tag 字段为 0000 0010 010(表示信息取自主存第 18 块)。
3.3. 小结#
优点:块冲突的概率最小;空间利用率最高;命中率高。
缺点:全相联映射方式的时间开销和所用元件开销都较大,实现起来比较困难,不适合容量较大的 cache。
为了加快比较的速度,通常每个 cache 行都设置一个比较器,比较器位数等于 tag 字段的位数。全相联 cache 访存时根据标记字段的内容来查找 cache 行中的主存块,因而它查找主存块的过程是一种“按内容访问”的存取方式,因此,它是一种“相联存储器”。
4. 级相联#
4.1. 原理#
前文提要:
根据不同的映射规则,主存块和 cache 行之间有以下 3 种映射方式。
- 直接:每个主存块映射到 cache 的固定中。
- 全相联:每个主存块映射到 cache 的任意中。
- 组相联:每个主存块映射到 cache 固定组的任意行中。
级相联即直接映射和全相联映射的结合体。
级相联是先把 cache 进行分组,分成固定的 个组,然后每个组有 行,每个主存块会被映射到固定的某一个组里的任意一行。
直接映射的做法:
将主存块划分为多个块群,每一个块群里,主存块的数量和缓存行的数量相同。这样每一个块群里的第一个主存块共享缓存里的第一个缓存行,每一个块群里的第二个主存块共享缓存里的第二个缓存行,以此类推。
全相联做法:
任意主存块都可被映射到任一空闲的缓存行
全相联可看为把主存映射到一个大的缓存组里,只不过该缓存组包含的缓存行数量是所有缓存行。
4.2. 实现方法#
级相联首先需要分组:规定一个数 ,将缓存分为 个内部缓存行数量相同的组;再确定组内缓存行的数量 。这样缓存就被分为:
主存里的每个主存块都会被映射到固定组的任一行里,即 “组间模映射,组内全相联” 的形式。映射规则为:主存块号 缓存组数 缓存组号
举例:假设 的缓存被划分为 ,则第 个主存块应该映射到缓存的第四组,因为 。
称 此类缓存的划分方式为 路组相联映射,当 ,称 路相联映射; ,称 路相联映射。
4.2.1. 存储结构#
级相联的存储结构划分为:
- 主存:组群( 个) 主存块( 个/组群)
- 缓存:组( 个) 组内缓存行( 行)
直接映射:
- 主存:块群( 组) 块群内主存块( 块)
- 缓存:缓存行( 行)
Note:级相联的”组群”术语只是为了和 cache 的组划分对应,实际上等于直接映射里的”块群”术语。
4.2.2. 映射规则:#
所以相比于直接映射,级相联改变的点只有 cache 的存储结构设计。在级相联里,cache 把直接映射里的”多个主存块映射到固定的同一 cache 行” 改为了 “多个主存块映射到 cache 的同一个 cache 组里”,避免这多个主存块始终竞争同一个缓存行。
在 cache 方面:把直接映射的”行”单位,改为了以”组”作为单位,一共划分为 个组,每个组有 行,让主存块映射时可以映射到固定的组里的任一行里,具体是哪一行,不关心。
在主存方面:为对应上 cache 的组划分,也把主存划分为 个组群,每个组群里一定有 个主存块,像直接映射一样,让每一个”组群”里的第 个主存块都共享 cache 里的第 个组,至于主存块在组里的哪一 cache 行,不关心。
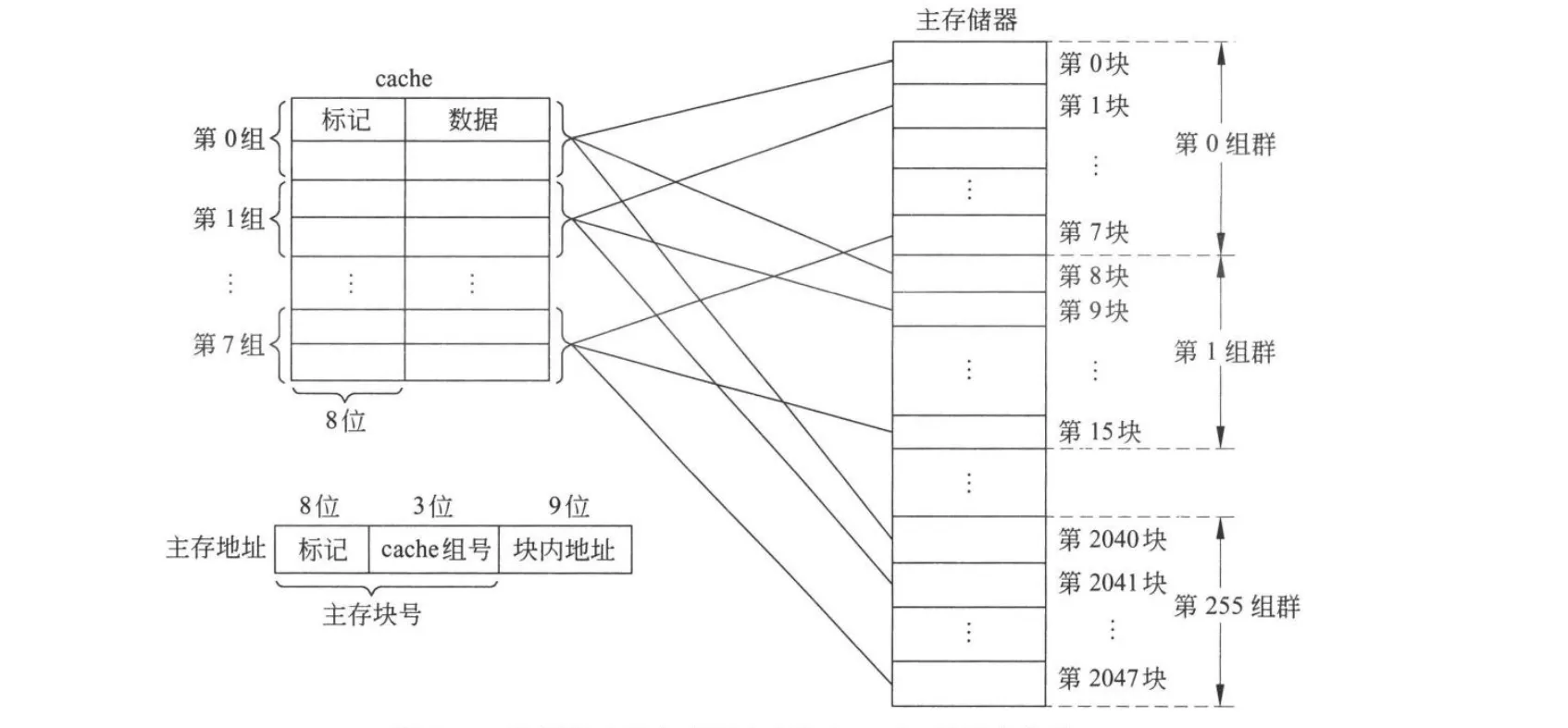
该图说明了上述的映射规则,每个组群的第 个主存块共享 cache 的第 个组里的 cache 行,组满时由替换算法进行数据替换。
综上,级相联相比于直接映射,只在 cache 的存储结构做了改动,并没有对主存的存储划分做任何改动。所以可知,直接存储是级相联的一种特殊形式,即 ,单路相联映射方式。
4.2.3. 主存地址空间划分:#
假设主存的地址为 ,即 位,块内地址为占 位;则可划分为 个组群,每个组群有 个主存块,则有关系式:
没有 是因为 是 cache 方面的划分,和主存无关
主存地址可划分为三个字段:

和直接映射一样,其中,高 位为标记(tag),中间 位为缓存组号,后 位是块内地址。
为了统一直接映射,也许可以记 tag 的符号为 ,块内地址符号为
一般主存、缓存的地址划分是这么划:
- 题目一般给出主存块容量,暗含块内地址空间位数
- 确认 ,即每一个 cache 组里有多少主存块(或者缓存行)
- 确认 :因为缓存较小,且主存块里每一个块群里的块数量 和缓存划分的组数量相同,因此从缓存方向确认 的大小。 缓存总容量除以
- 确认 :主存容量一般给出,设为 位,则
例题:假定 cache 数据区容量为 ,每个主存块大小为 ,按字节编址,则块内地址的位数 ;采用 路组相联,即每组有 行,则 cache 有 组,即 。假定主存地址为 位,则 ,即主存共有 个组群,每个组群有 块,每块有 字节,因而主存地址划分为标记 位、组号 位、块内地址 位。
提问:为什么组群数等于标记 tag 的位数?
回答:
首先回到直接映射,设标记位数为 ,则主存块群数量为 。再看主存映射的方式,主存是通过对主存块序号进行取模,进而得到该主存块是映射到那一缓存行的;知道哪几个主存块映射到同一缓存行后,再通过缓存行存储的 tag 字段确认当前存储的主存块位于哪一个块群的。这说明了一件事:可以通过 tag 字段分辨该主存块位于哪一个块群(已知具体的的缓存行号 )。那么,究竟能划分多少个块群呢? 因为 tag 字段有 位,显然可划分 个块群。但注意:这只是确认了主存可被划分为 个,但主存的实际容量可能不支持存储 个块群,也就是说,划分的部分块群是空的(不存在的),CPU 永远不会访问到(实际上由于物理上不存在,CPU 也不可能访问到)
由此我们可以得到两个结论:
- 在根据 cache 行号找到正确的 cache 行后,tag 字段用于指示该主存块位于哪一个块群,同时用于在 cache 里进行缓存行比较,确定主存块存在于 cache
- 理论上 tag 字段指明了主存可以被划分为完整的 个块群,每一个块群有 块;但实际上主存容量不一定有 这么大,可能比这容量小,但又比 大,因此会有部分主存块物理上不存在,CPU 无法访问
现在再来看级相联,级相联和直接映射相同,只不过划分单位改为了组。tag 字段位数为 ,说明主存可划分为 个群组,即主存容量可划分为:
4.3. CPU 访存过程#
首先根据访存地址中间的 位 cache 组号,直接找到对应的 cache 组,将对应 cache 组中每个的标记与主存地址的高 位标记进比较,若有一个相等并且有效位为 ,则称访问缓存命中,此时,根据主存地址中的块内地址,在对应 cache 行中存取信息;
如果访存地址和 cache 组里的所有 cache 行的标记都不相等,或者相等但是有效位为 ,则称缓存缺失,此时,CPU 从主存中读出该访存地址所在的主存块,并送到 cache 对应组的任意一个空闲行中,将有效位置 ,并设置标记,同时将该地址中的内容送 CPU。
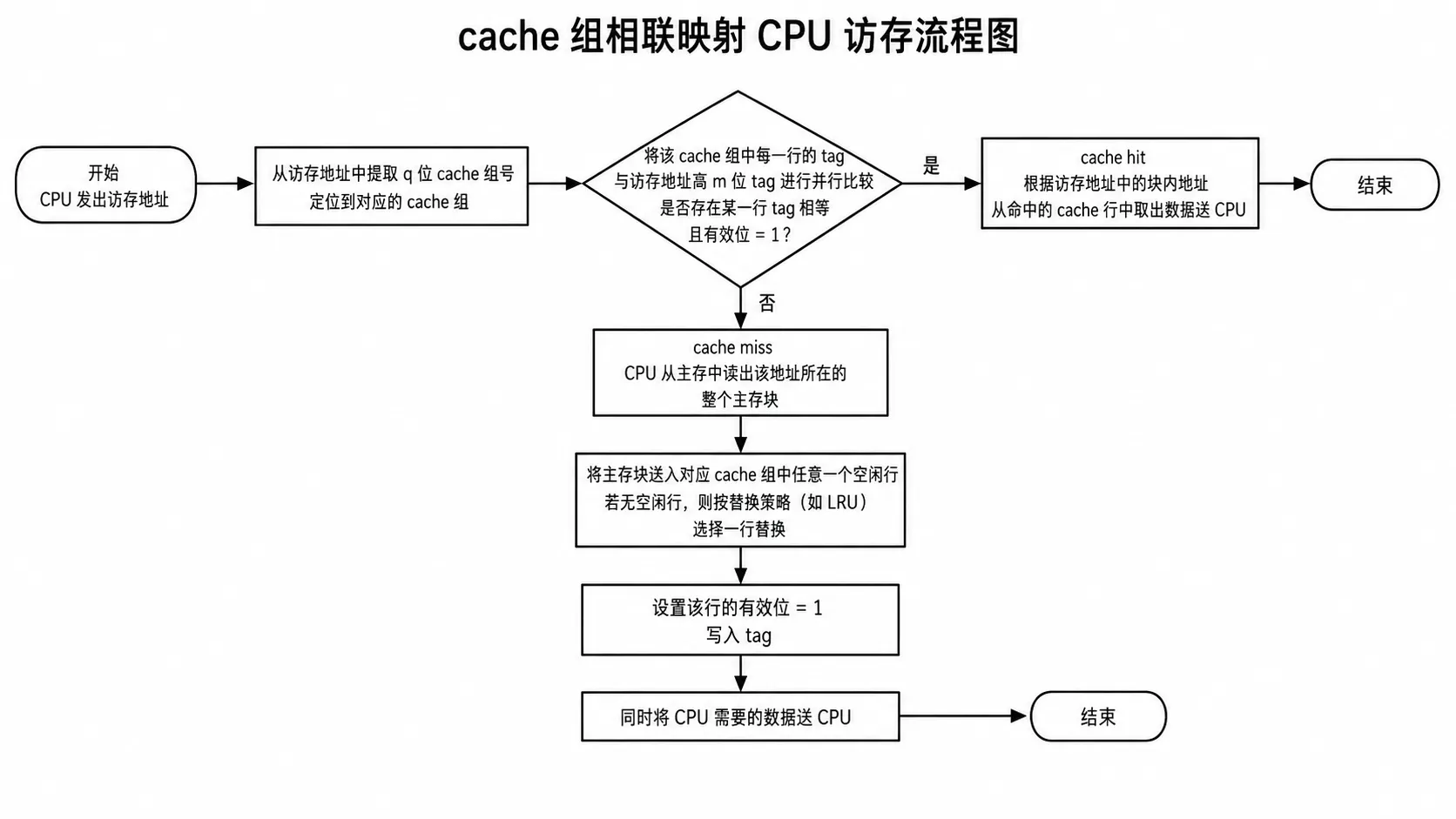
4.4. 例题#

由题,块大小为 ,则 cache 容量为:
可得 ( 已给出)。
主存地址划分为:
因此,主存地址划分为:块内地址位数 ,每个组群的主存块位数 ,一共划分为 位数的组群。
映射关系如图:
主存地址 0240CH 展开为二进制数为 0000 0010 0100 0000 1100,所以主存地址划分为:

访问过程如下:
- 根据 MAR 提供的地址(即
0240CH)中间的010定位到 cache 里的第 组 - 将 tag 字段
0000 0010与 cache 的第二组里的两个 cache 行里的数据的 tag 字段进行比较 - 如果存在一个 cache 行的 tag 字段匹配成功(matched),且有效位为 ,则称为 cache hit
- 根据块内地址
0 0000 1100读取该 cache 行里的相应的地址单元的数据,送入 CPU - 如果没有匹配成功,或者有效位为 ,则称为 cache miss
- 此时,访问主存里的目标主存块(地址为
0000 0010 010),将主存块复制到正确的 cache 组里的任一行,即 cache 第 组里的任一 cache 行,同时把块内地址为0 0000 1100的数据送入 CPU
5. 三种方式比较#
组相联映射式结合了直接映射和全相联映射的优点。当 cache 的组数为 时,变为全相联映射;当每组只有一个 cache 行时,则变为直接映射。组相联映射的冲突概率比直接映射低,由于只有组内各行采用全相联映射,所以比较器的位数和个数都比全相联映射少,易于实现,查找速度也快得多。
对于个主存块来说, 种映射式下对应的 cache 行数不同:
- 直接映射:唯一映射,每个主存块都只有一个固定的 cache 行与之对应,它只能映射到这个 cache 行
- 全相联映射:任意映射,每个主存块都可映射到 cache 里的任一行
- 路级相联:每个主存块可映射到 个 cache 行(即某一组里的 行)
因此可引入一术语”关联度”来衡量这种关系。关联度是指一个主存块映射到 cache 中时可能存放的位置个数(可被映射到多少个 cache 行)。显然,直接映射的关联度最低,为 ;全相联映射的关联度最高,为 cache 的总行数; 路组相联映射的关联度居中,为 。
当 cache 大小、主存块大小一定时,关联度和命中率、命中时间、标记所占额外开销等有如下关系。
- 关联度越低,命中率越低。因此直接映射命中率最低,全相联映射命中率最高。
- 关联度越低,判断是否命中的时间开销越小,命中时间越短。因此,直接映射的命中时间最短,全相联映射的命中时间最长。
- 关联度越低,tag 字段所占的额外空间开销越少。因此,直接映射额外空间开销最少,全相联映射额外空间开销最大。
例题:

缓存总行数 ,主存块大小为
当关联度为 时,,即直接映射,此时 ,可得 ,即 tag 字段的位数为 ,因此 tag 字段在缓存里所占总位数为 ,因为一共有 行 cache 行。
同理,当关联度为 ,即 路级相联映射,,则 ,即每个主存块(或者缓存行)的 tag 字段位数为 ,因此 tag 字段的总位数为 。
关联度为 ,则 tag 位数 ,因此 tag 字段的总位数为 。
全相联下,cache 的组数为 ,主存块地址划分为“tag 字段 + 块内地址”,因此 ,因此 tag 字段的总位数为 。