重点#
- 给定代码片段,可分析其时间局部性、空间局部性的优劣
- CPU 的平均访问时间计算
1. 程序访问局部性#
实践表明,某一个程序在运行时,其被分配的地址往往集中在存储器的一个很小的范围内,这种现象称为程序访问的局部性,包括时间局部性和空间局部性两种。
时间局部性是指被访问的某个存储单元在一个较短的时间间隔内很可能又被访问;空间局部性是指被访问的某个存储单元的邻近单元在一个较短的时间间隔内很可能也被访问。
- 时间局部性:如果存储某条指令或者数据的存储单元在当前时刻被访问,那么很可能在一个较短的时间间隔后会被再次访问。(该存储单元可能被频繁访问)
- 空间局部性:如果某个存储单元在当前时刻被访问,那它临近的存储单元可能在一个较短的时间间隔内被访问。
总结:如果某个存储单元被访问,那么不久的将来它和它相邻的存储单元都很有可能会被(再次)访问。
出现程序访问的局部性特征的原因如下。因为程序是由指令和数据组成,而指令在主存中按顺序存放,其地址连续,循环程序段或子程序段通常被重复执行,因此,指令的访问具有明显的局部化特性。而数据在主存中一般也是连续存放,特别是数组元素,常常被按序重复访问,因此,数据也具有明显的访问局部化特征。
即指令和数据都经常出现重复执行的情况,因此被重复访问的概率很高
高速缓冲技术正是利用局部性原理,将程序当前活跃的部分数据暂存于容量小但速度极快的 Cache 中,使 CPU 的多数访存操作直接在 Cache 中完成,从而显著提升程序执行效率。
以两个代码片段的分析为例,介绍如何分析程序访问的局部性。

假定 、 都为 ,按字节编址,每个数组元素占 字节,则指令和数据在主存中的存放情况如图所示。
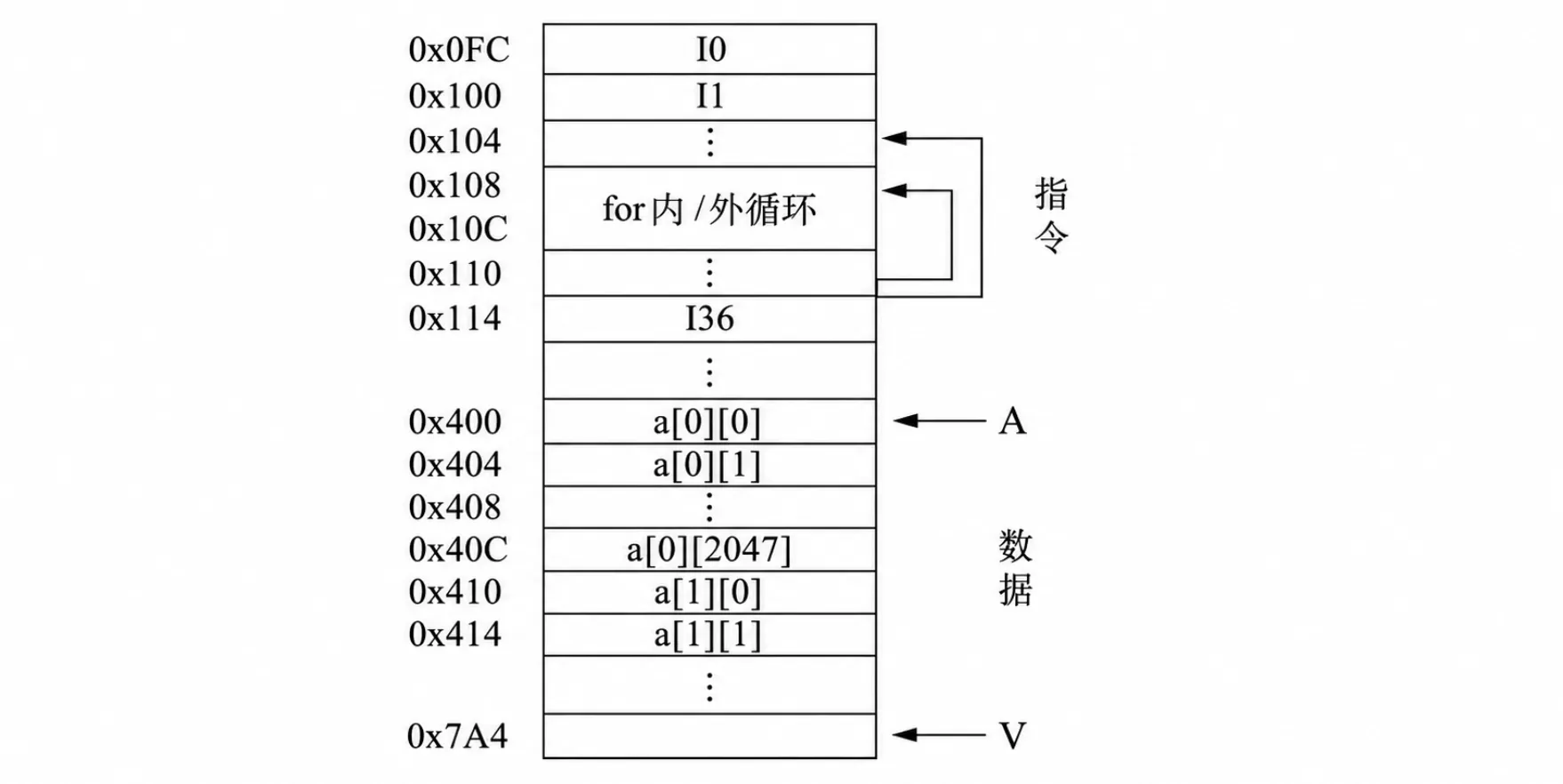
假定 、 都为 ,按字节编址,每个数组元素占 字节,则指令和数据在主存中的存放情况如图所示。
1. 对于数组 a:
程序 对于数组 的访问是顺序访问,即从a[0][0] a[0][1] … a[1][2047] ,访问顺序和存储顺序一致,空间局部性较好,因为可以更频繁地访问到当前存储单元的相邻单元,即访问到相邻存储单元的概率很高。
而程序 在访问数组 时,每一次都要越过 2048 个数据元素,如果按字节编址,那就是 8192 个存储单元(一个存储单元存储一个字节,或者说一个字为一字节)。如果 CPU 与 cache 的交换单位(单次访问的数据量)小于 ,那么每次将一个主存块装到 cache 时,下个要访问的数组元素总不能被装入缓存,因而没有空间局部性。
而数组 的时间局部性在两个程序片段里都很差,因为每一个数据元素都只被访问一次(时间局部性要求该存储单元是频繁被访问的)。
2. 对于 for 循环体:
我们关注的不再是数据,即变量,而是指令的存储单元和访问概率。
程序片段 和 的程序访问局部性相同,因为指令都是按照顺序连续存储和访问,即从地址 连续访问到 ,然后又从 连续访问,因此空间局部性好。而内部的指令被连续执行了 次,即 for 循环体的每个指令的存储单元都被访问了这么多次,时间局部性也很好。
综上:由于数据变量 的访问逻辑不一样,造成了两个代码片段的空间局部性的较大差异,导致了程序执行时间的不同。
曾有人将这两个程序()放在 2GHz Pentium4 上执行以进行比较,其实际运行结果为:程序段 的执只需要 个时钟周期,而程序段 则需要 个时钟周期。程序段 A 比程序段 B 快了将近 倍!
2. cache 工作原理#
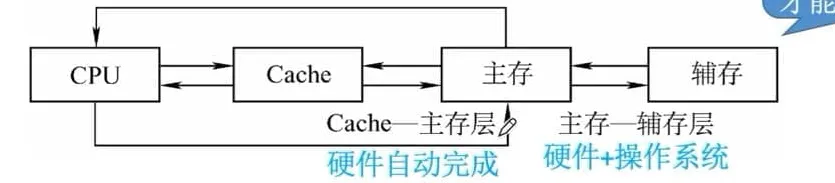
cache 是一种小容量高速缓冲存储器,由快速的 SRAM 组成,直接制作在 CPU 芯内,速度几乎与 CPU 一样快。在 CPU 和主存之间设置 cache,把主存中被频繁访问的程序块和数据块复制到 cache 中。由于程序访问的局部性,大多数情况下,CPU 能直接从 cache 中取得指令和数据,而不必访问主存。
2.1. cache 的存储格式#
为便于 cache 和主存间交换信息,cache 和主存空间都被划分为大小相等的块。
主存中的区域称为块(block),也称为主存块,它是 cache 和主存之间的信息交换单位。
cache 块又称 cache 行(line)或 cache 槽(slot),每块由多个字节组成,块的长度称块长(行长)。
因为 Cache 的容量远小于主存的容量,所以 Cache 中的块数要远少于主存中的块数,Cache 中仅保存主存中最活跃的若干块的副本。因此,可按照某种策略预测 CPU 在未来一段时问内待访存的数据,将其装入 Cache,即后续提到的替换算法。
2.2. cache 的有效位#
在系统启动或复位时,每个 cache 行都为空,其中的信息无效,只有装人了主存块后信息才有效。为了说明 cache 行中的信息是否有效,每个 cache 行需要一个有效位(valid bit)。有了有效位,就可通过将有效位清零来淘汰某 cache 行中的主存块,称为冲刷(flush),装人一个新主存块时,再使有效位置 1。
2.3. CPU 在 cache 中的访问过程#
CPU 执行程序过程中,需要从主存中取指令或读数据时,先检查 cache 中有没有要访问的信息,若有,就直接从 cache 中读取(称 cache 命中 hit),而不用访问主存;若没有(称缺失 miss),再从主存中把当前访问信息所在的一个主存块复制到 cache 中,因此,cache 中的内容是主存中部分内容的副本。
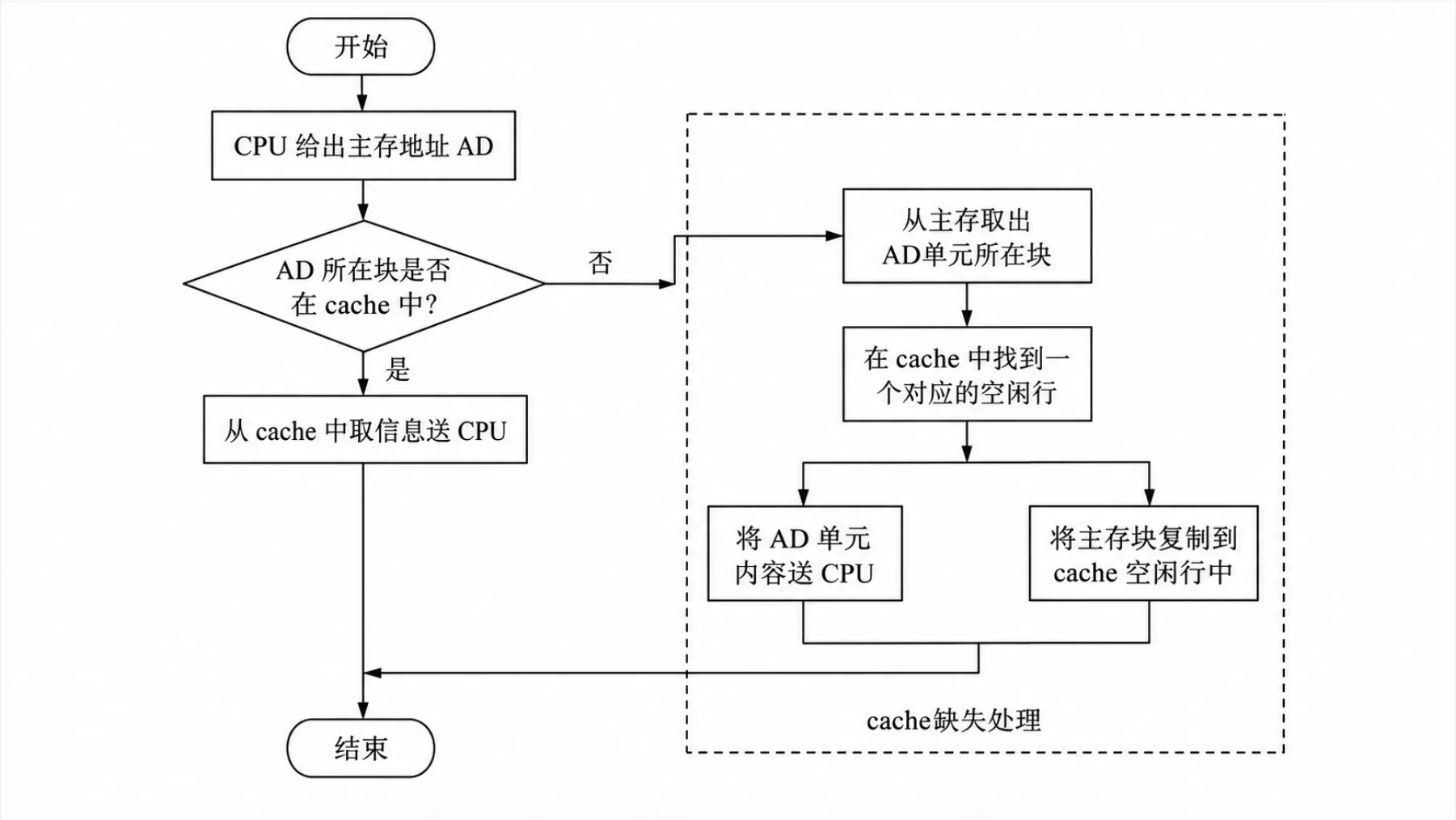
如图所示,整个访存过程包括判断信息是否在 cache 中,从 cache 中取信息或从主存中取一个主存块到 cache 等工作。
如果 AD 所在块在 cache 里,则称为 cache hit;如果不在,称为 cache miss,需要访问主存获取目标块,并且将该主存块写入 cache 块里。
如果对应 cache 行已满而找不到空闲行时,需要使用替换算法选择合适的 cache 块,将新的主存块存放到该 cache 块中。
整个访问过程(包括命中判断、块调入、替换等)必须在单条指令执行周期内完成,因此完全由硬件实现。Cache 机制对程序员是透明的,程序员不需要编程时考虑信息存放在主存还是 cache。
2.4.cache-主存层次的平均访问时间#
在 CPU 访存过程中,需要判断所访问信息是否在 cache 中。若在 cache 中,称为 cache 命中,即 cache hit;如果未命中,称为 cache 缺失(cache miss)。
cache 命中的概率称为命中率 (hit rate), 等于命中次数与访问总次数之比。cache miss 概率称为缺失率,显然,缺失率为 。
命中时,CPU 直接从缓存里读取数据,此时需要的时间开销为访问 cache 的时间 。未命中时,需要从主存读取一个主存块送入缓存,同时送入 CPU,此时时间开销为 。其中 为 CPU 访问主存的时间开销,同时 也成为缺失损失(miss penalty),即从主存读入一个主存块到缓存的时间。
- :缓存命中时,CPU 读取数据的时间开销,称为命中时间。
- :从主存读入一个主存块到 cache 的时间。
- :cache miss 时,CPU 读取数据的时间开销。由上图,即主存块复制到 cache 加上数据送入 CPU 的总时间
则 CPU 在 cache-主存层的平均访问时间为:
当 时,。即由于程序访问的局部性原理,缓存往往很高,因此 CPU 的平均访问时间接近于缓存命中时间。
例题#
例一#


例二#

设命中时间为 ,则 CPU 直接从主存读取数据的时间为 ,。
严格来说是缺失损失,即从主存读入一个主存块到 cache 的时间。而”主存的存取时间”是指 CPU 访问主存一次的时间,即发出地址到数据到达的时间。
在单字宽存储器、每块只有一个字的简化模型下,一个主存块就等于一个字,因此读取一个块就等于一次存取时间,此时 = 主存存取时间,所以这道题是简化的单字模型,因此才可使用 表示平均的缓存缺失的访问时间。
单字宽存储器下如果一个主存块有 个字,那么 ,因为需要串行读取 次,才可完整获取一整个主存块。
该题很简单,使用 cache 后,平均访问时间
未使用 cache 时,平均访问时间为 ,因此性能提升了 倍。